

为您介绍 IDC 1411,这是一款利用人工智能技术实现实时语音识别与背景噪音区分的设备
IDC 1411 的最大延迟仅为 4 帧,非常适合专业视听、现场直播和后期制作!
该模块最初的设计目的是为听力受损的观众提供增强的语音通道,它可以用于多种用途,例如为 AI 驱动的字幕和翻译生成器预先清除语音,或者在安全服务中隔离监视情况下的语音。
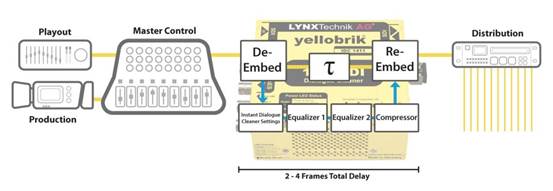
它不仅仅是一款降噪工具,还能全面控制背景和对话音量。除了基础音量调节功能外,它还配备两个均衡器和一个压缩器,可进行高级微调。音频输入可从 12G-SDI 输入流解嵌,或从外部 AES 输入获取。增强型对话音轨可嵌入回 SDI 输出流,或路由至专用 AES 输出。

单个模块中的多路音频流处理
演播室音频通常可以得到严格控制和平衡,但户外广播的背景噪音却不受制作团队的控制。在一些嘈杂的环境中,可以使用降噪或超近距麦克风,但在新闻采集或有不可预测的观众或环境噪音的活动中,这并非总是可行。与需要多个设备的捕捉点降噪或滤波系统不同,IDC 1411 集成到了制作工作流程中,因此每个传输通道可能只需要一个单元。通过与 yellobrik RCT 和 SRV 模块的 SNMPv2 完全集成,IDC 1411 可以在制作过程中随意启用和禁用,并根据需要快速远程重新配置。
让我们听听在这现实世界中效果如何
现场体育赛事制作:将人群噪音调低至所需水平。
新闻采访:减少交通、人群和嘈杂的背景噪音。
操作简便——助您轻松实现精准调节
功能说明:
对话增强强度调节:可设定整体对话的清晰度与净化效果
语音增益调节:支持对语音信号进行增益调整,可提升或衰减语音音量(dB)。
背景增益调节:支持对背景噪声进行动态控制,可降低或增强背景音效(dB)。

为实现更强大的功能扩展与精细化调节,系统额外配置了两个独立均衡器。每个均衡器均支持中心频率、增益及带宽参数的调节,并集成了一款支持立体声联动的音频压缩器,具备阈值、压缩比率以及启动时间和释放时间等调节功能。
核心功能特性
• 支持通过光纤或铜缆传输 1.5G、3G 以及 12G/4K SDI 视频输入
• 完全兼容 AES3id 或通过光纤传输的 AES 数字音频信号(需选配 SFP 模块)
• 提供语音增益、背景增益、动态压缩器及两个独立均衡器的参数调节功能
• 自动应用视频延迟补偿,避免视音频不同步现象
• 操作学习曲线平滑,5 分钟即可掌握基础操作,10 分钟实现熟练应用
• 创新性音频处理技术,显著提升画面内容表现力
• 有效降低对额外设备及专业人员的依赖
• 支持通过专业控制软件进行参数配置与信号路由管理
• 可通过 LynxCentraal 或 yelloGUI 实现全面远程操控

yellobrik产品的卓越适应性
它也适用于固定的工作室安装,并且可以安装在我们的 1RU 机架中,该机架提供主电源和备用电源保护,以及通过我们的 LynxCentraal 应用程序实现全面远程控制和监控。
